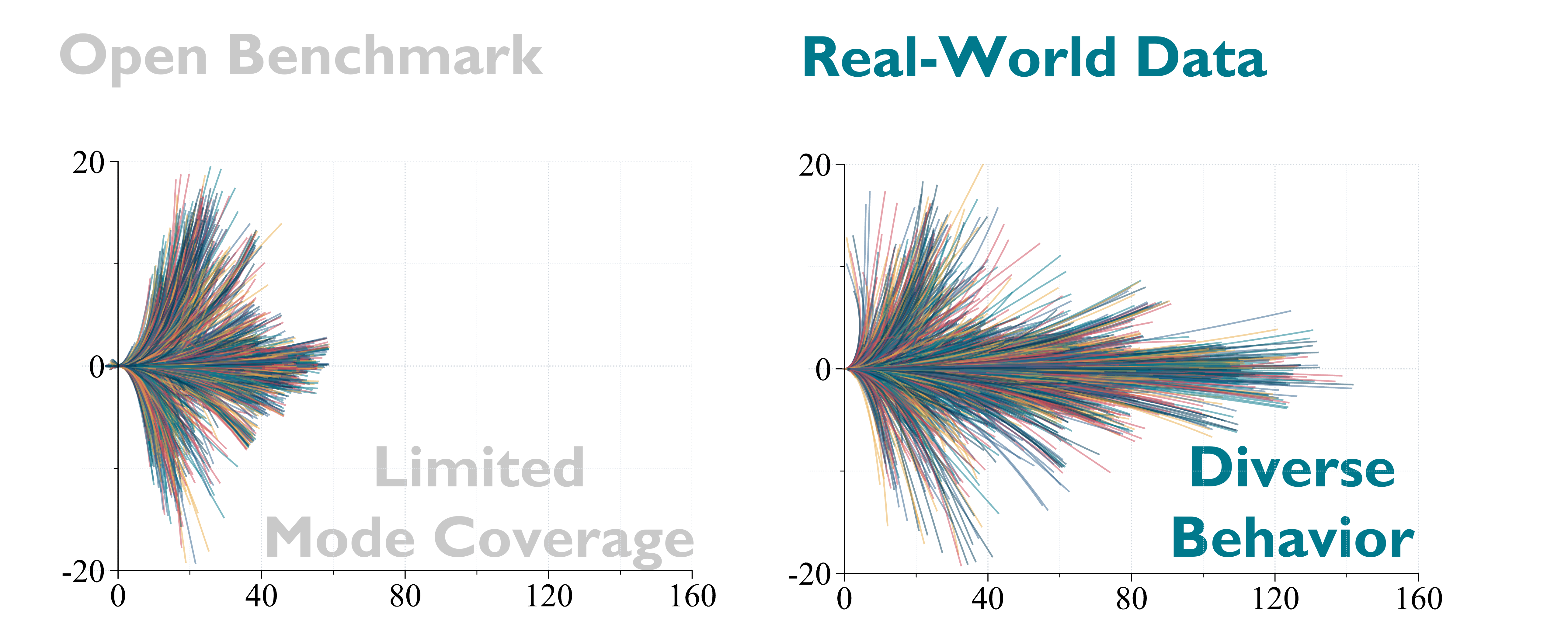
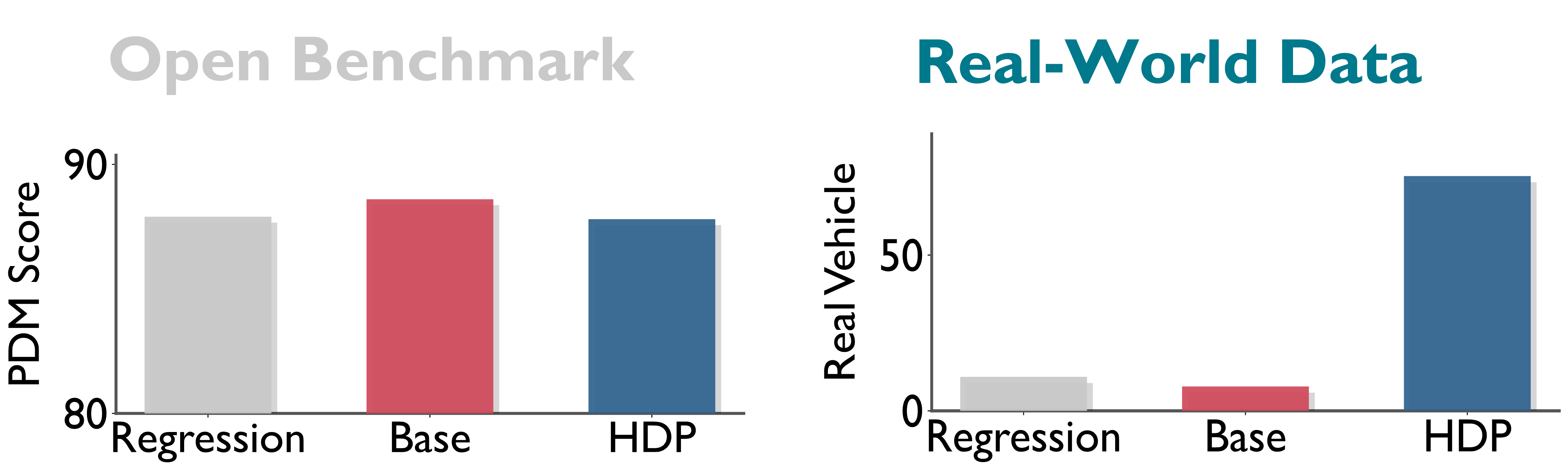
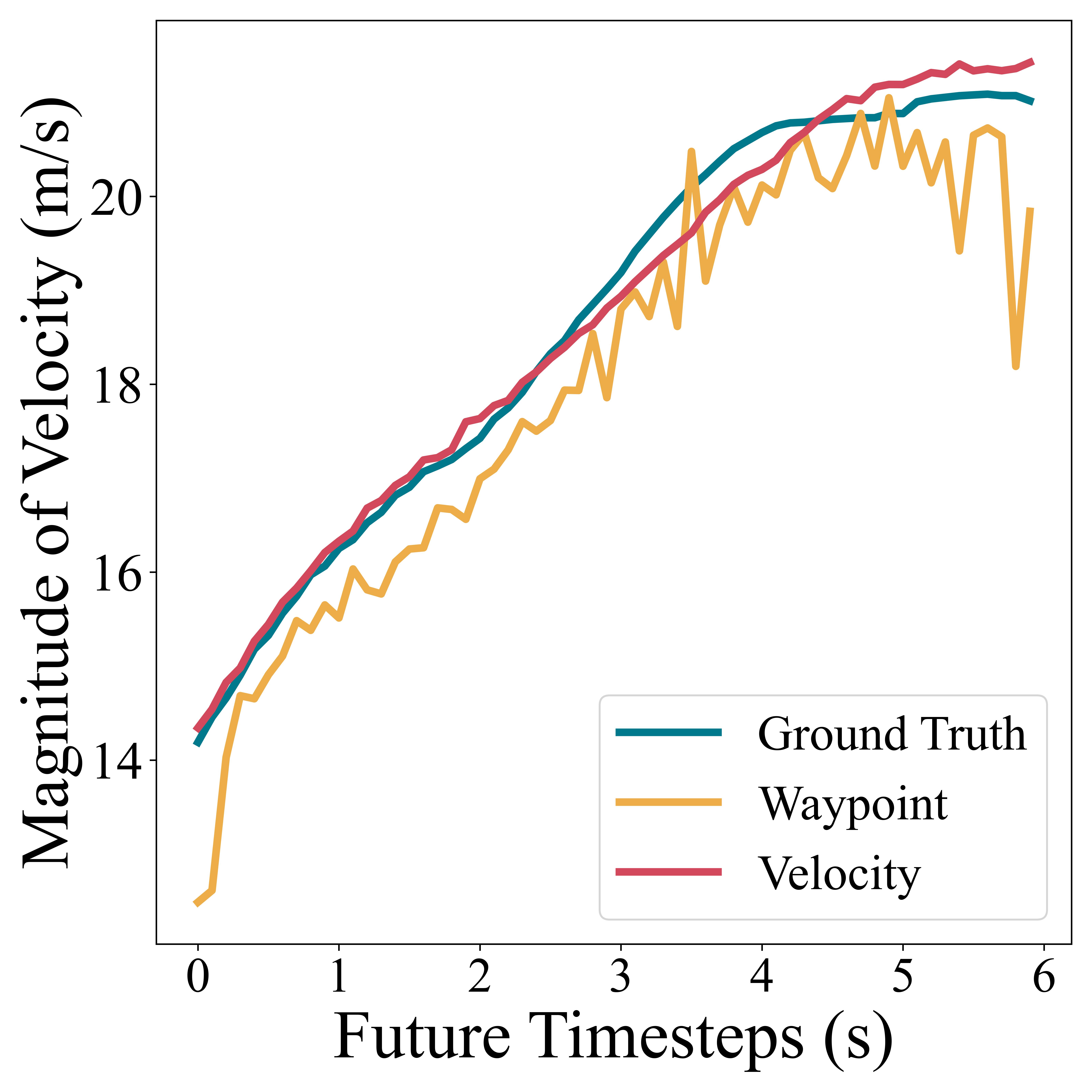
4 — RL Post-Training
Imitation learning produces a strong behavioral prior but provides no explicit safety constraint—a
critical gap for deployment. We close it with an RL post-training stage that directly
optimizes a safety-aware reward while keeping the entire diffusion architecture intact.
We formulate a KL-regularized policy optimization objective that constrains the
updated policy to stay close to the referece policy. Its closed-form solution is an elegant
reward-reweighting: the existing Hybrid Loss is simply multiplied by exp(β·r),
where r is a collision-based safety reward.
Why not diffusion PPO? Many diffusion RL methods decompose denoising into a multi-step MDP
and apply PPO to each step, requiring fine discretization for Gaussian validity, storing gradients
for all steps, and incurring high variance.
Our approach is a simple weighted regression—same training pipeline, minimal overhead,
and provably compatible with the Hybrid Loss P-norm.
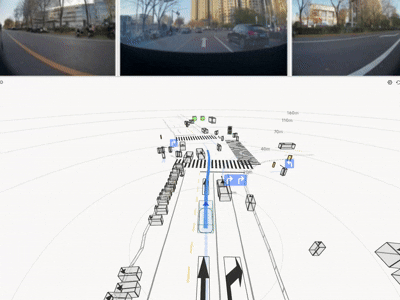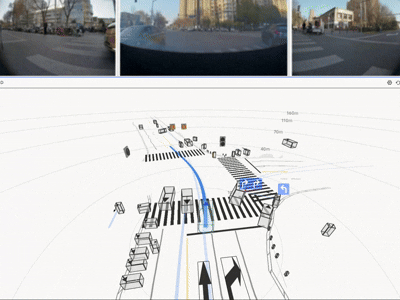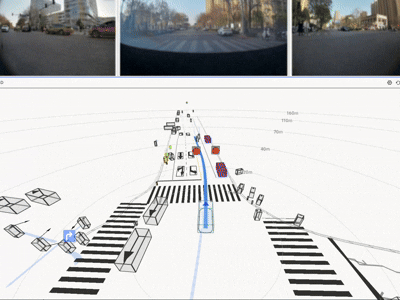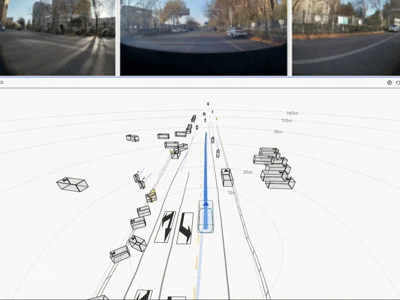
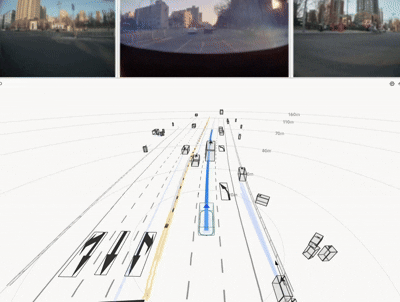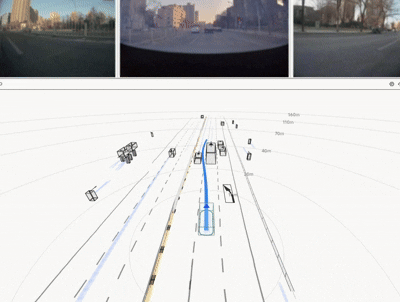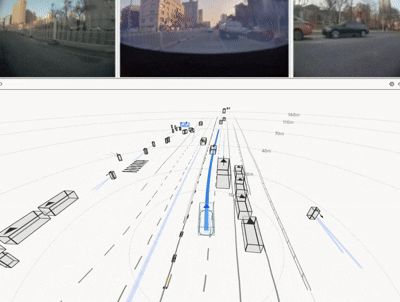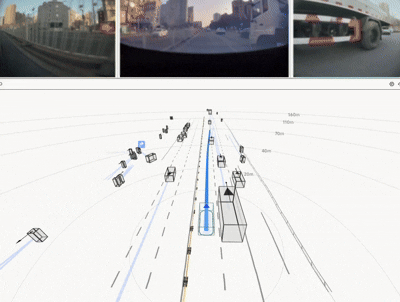
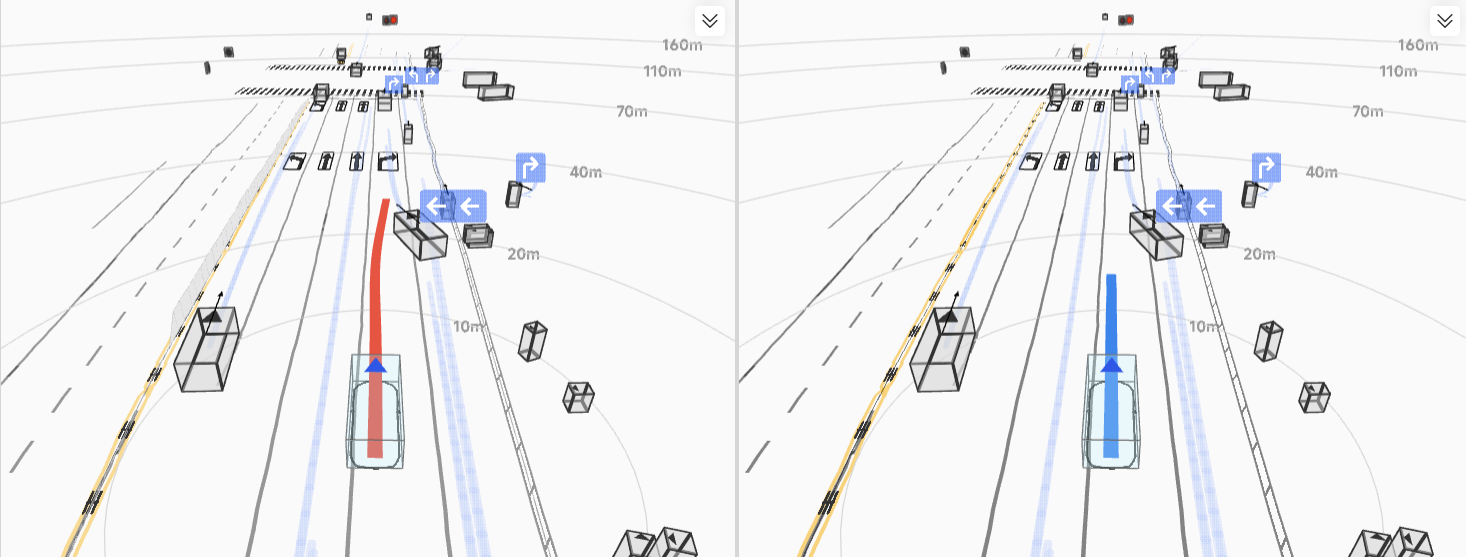
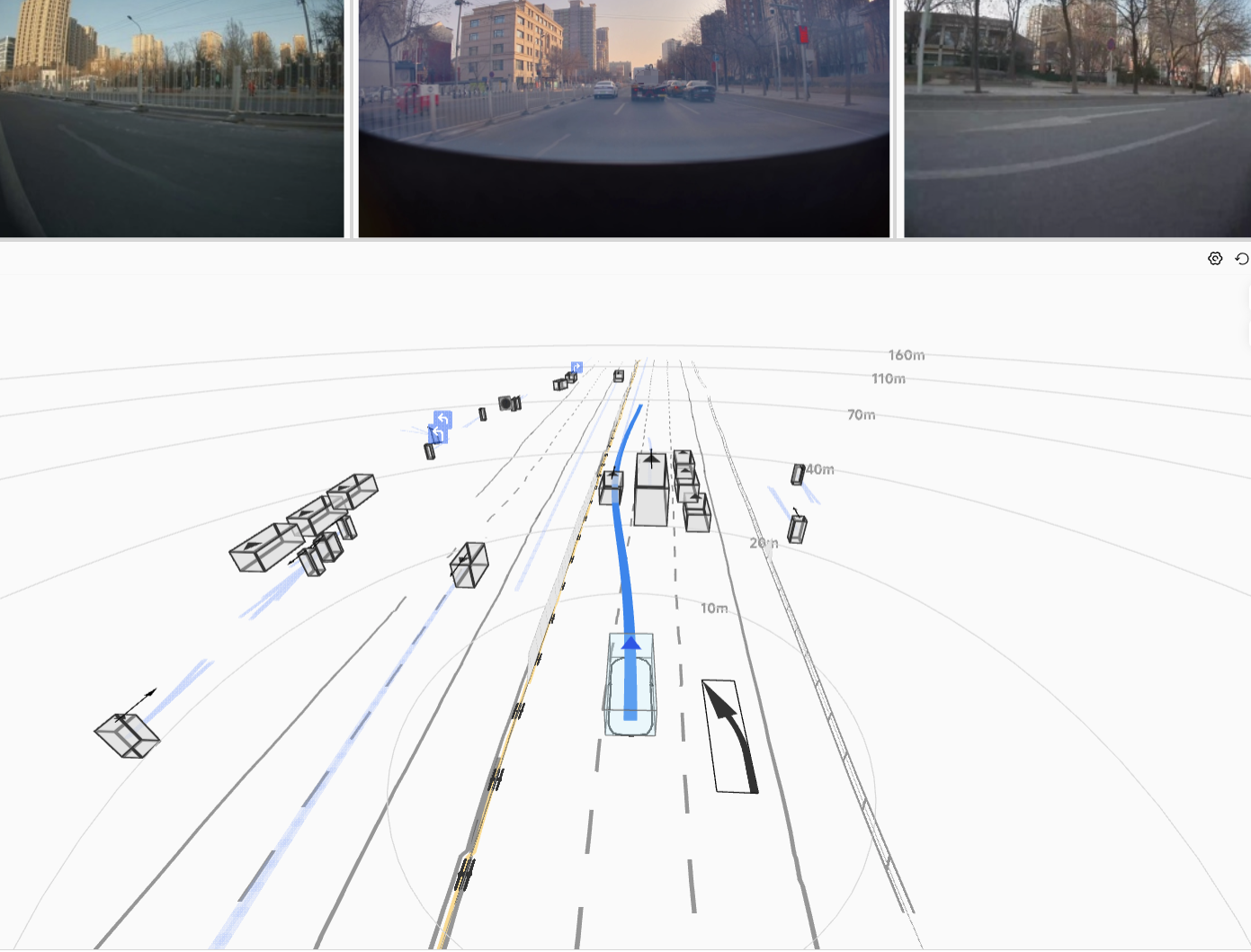
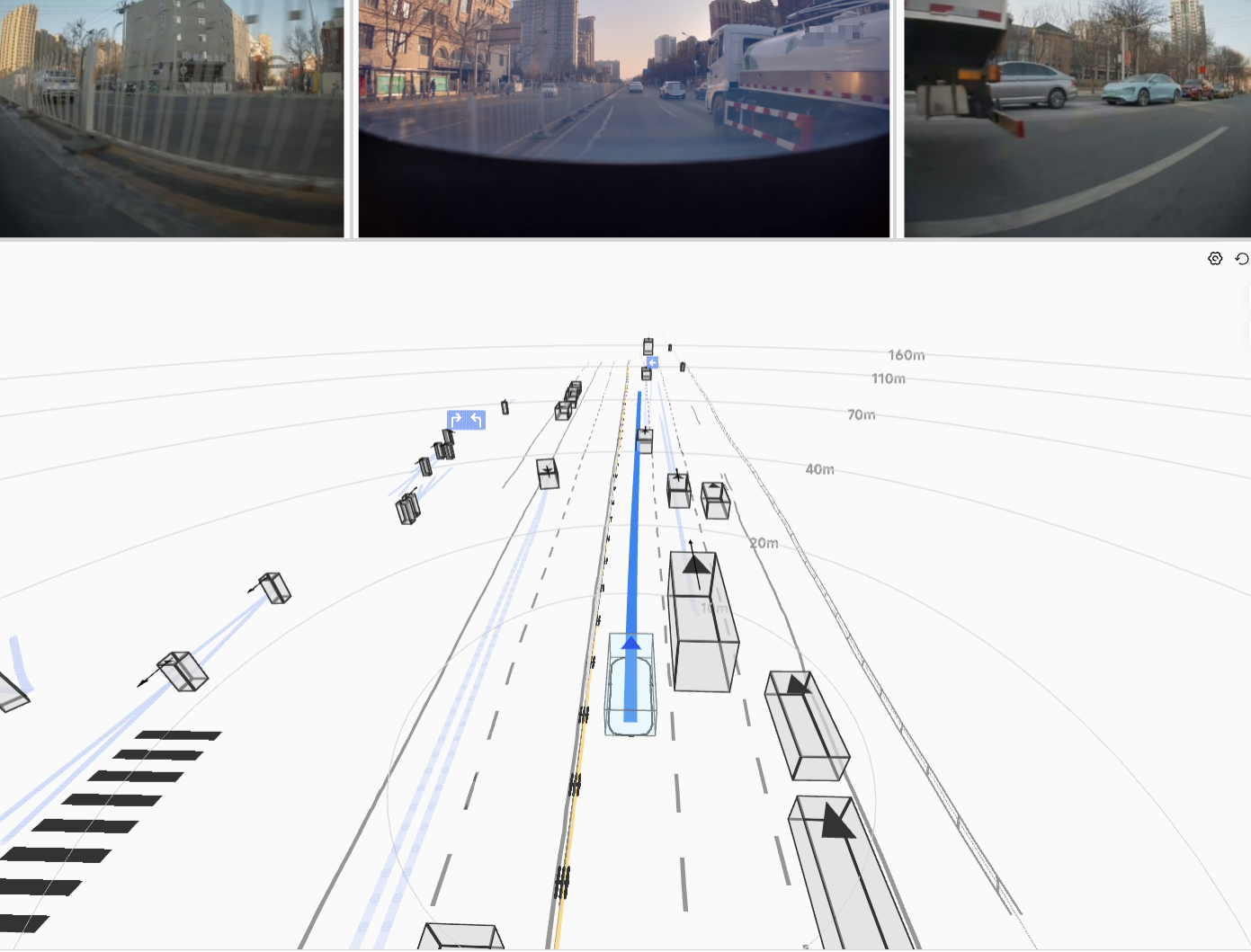
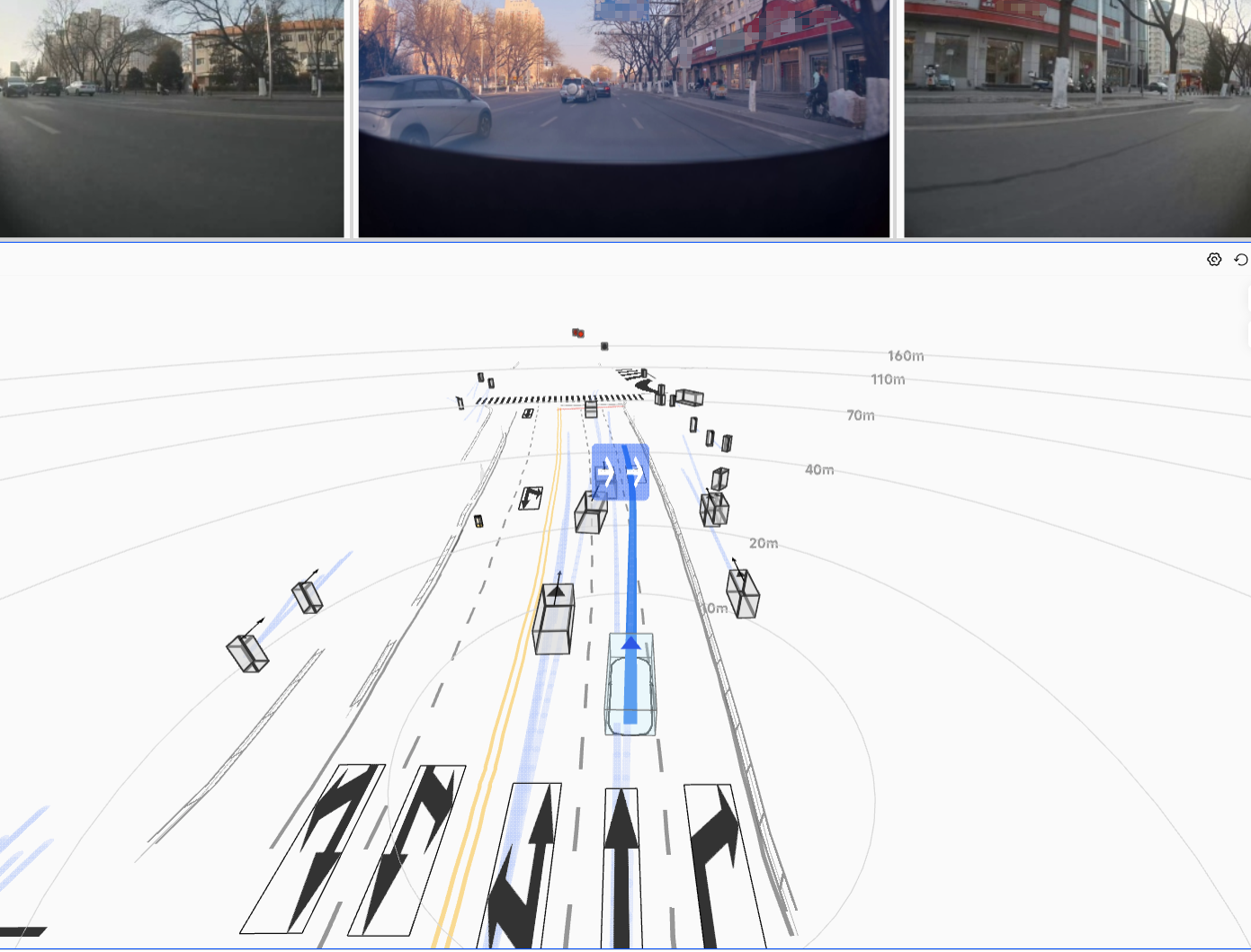
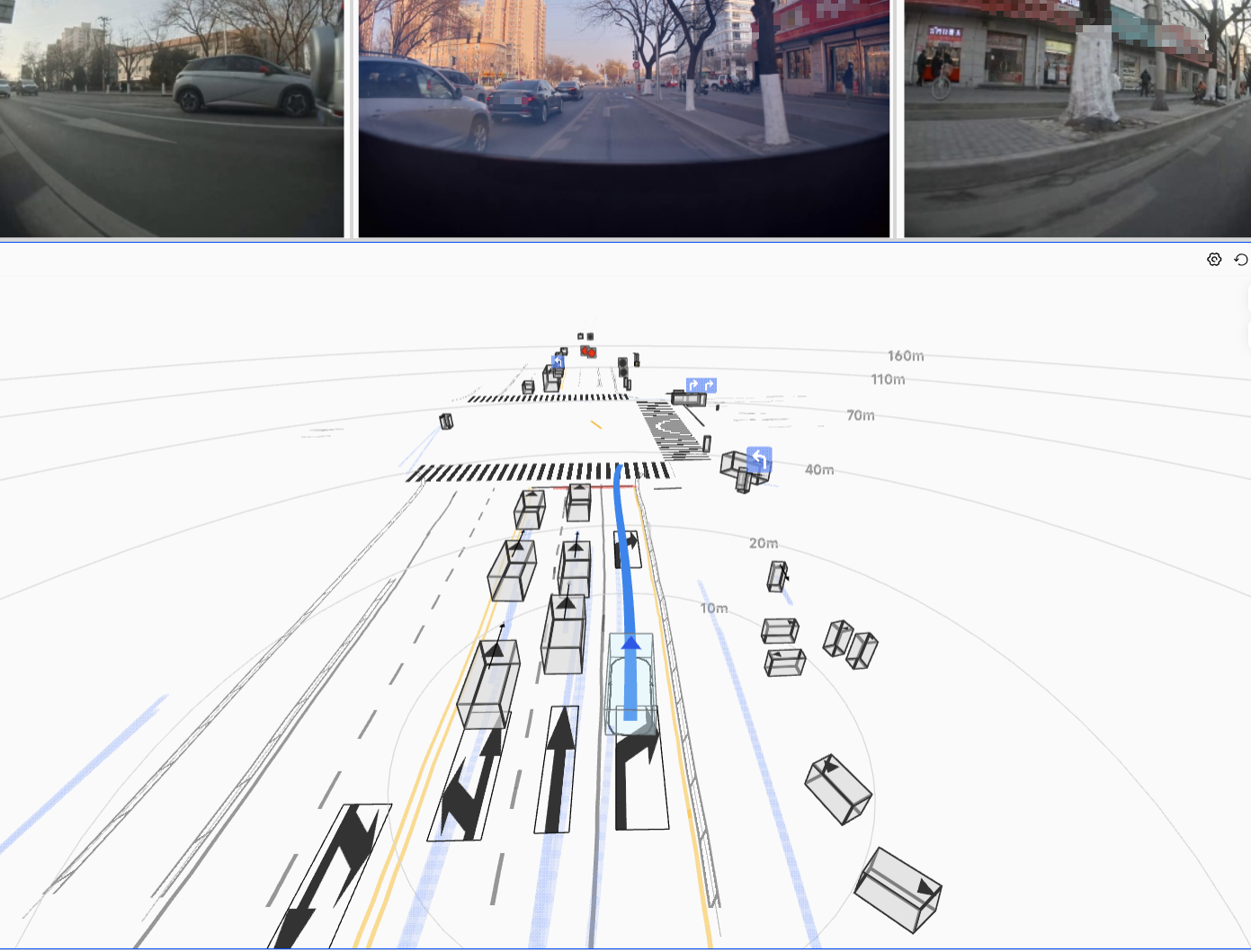
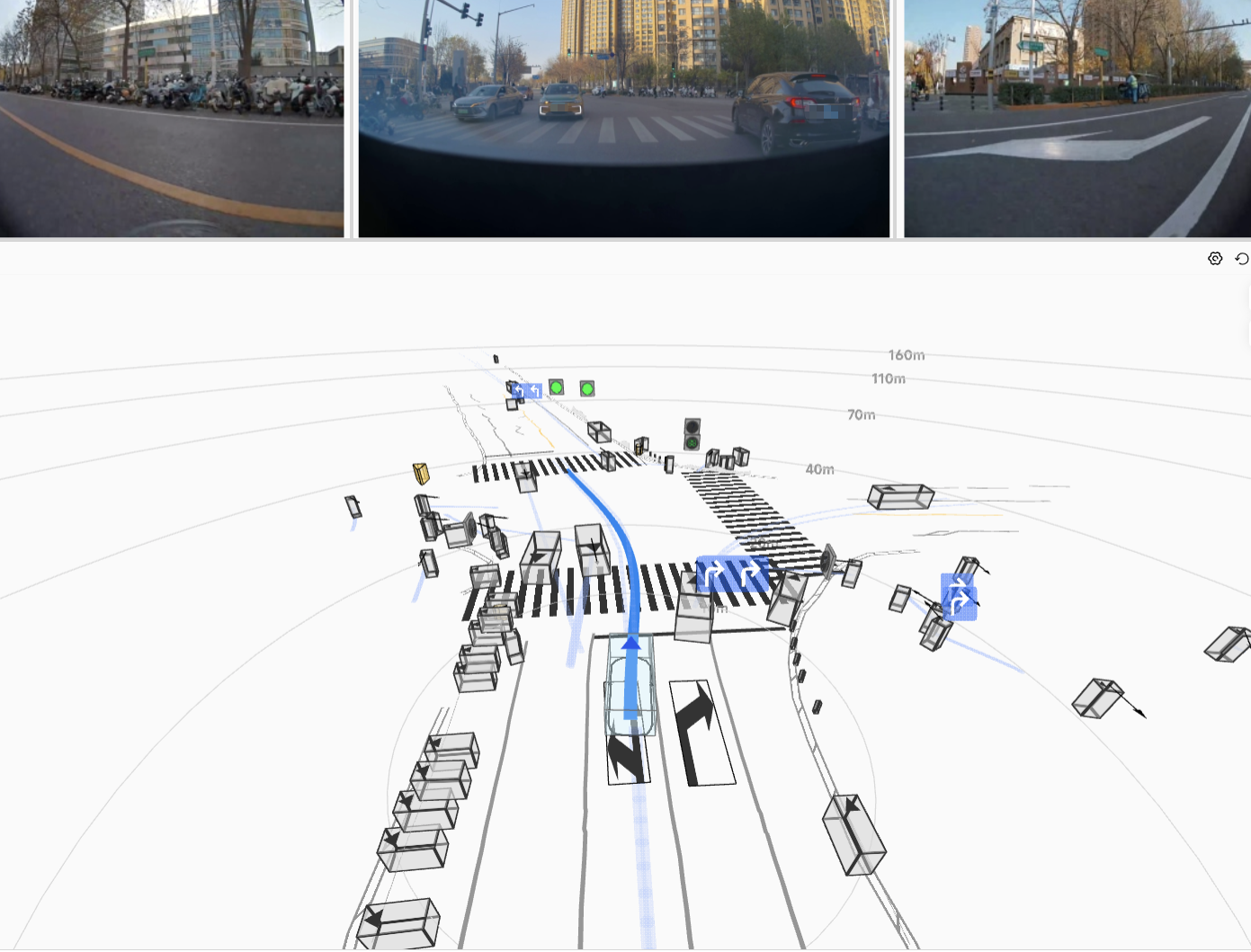
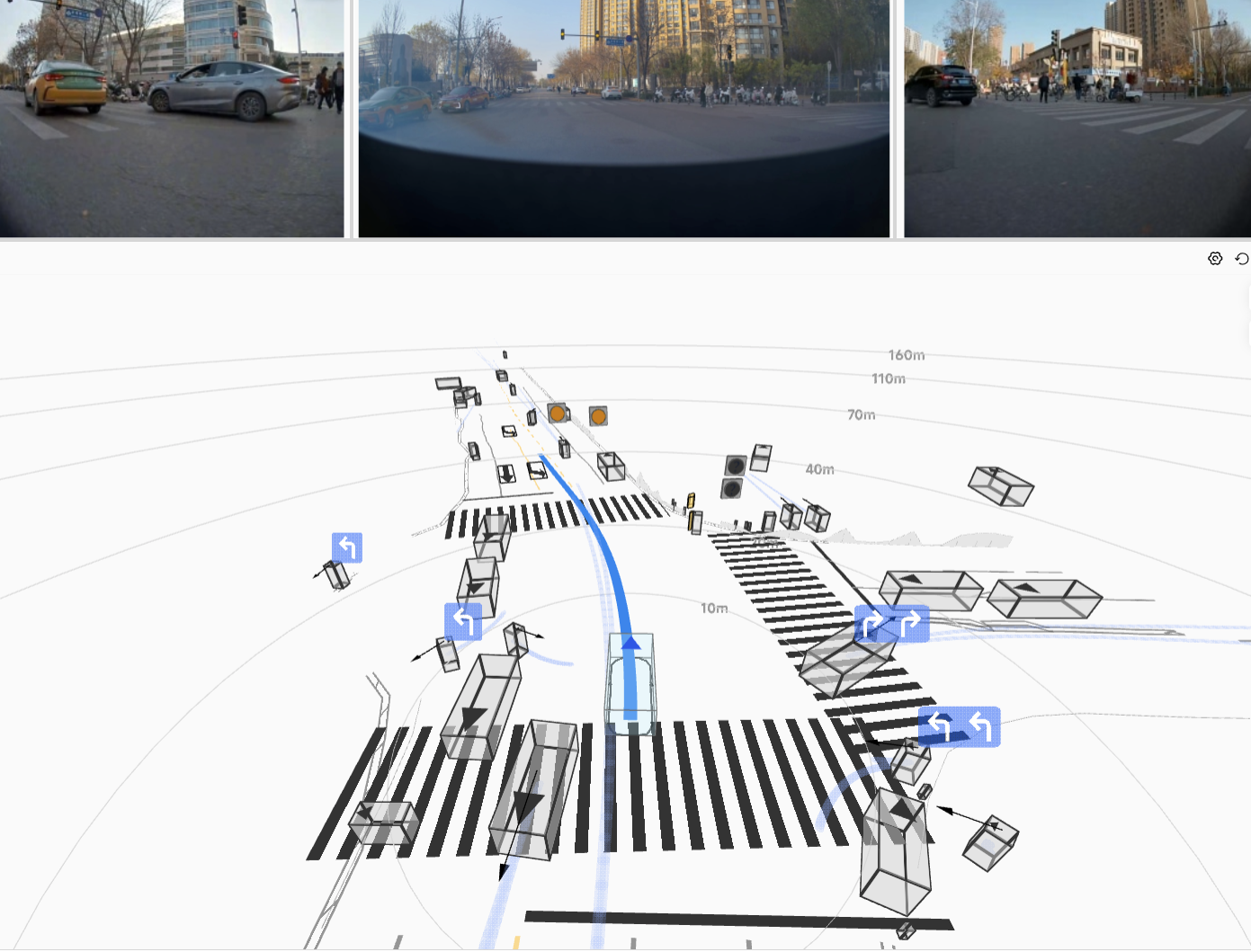
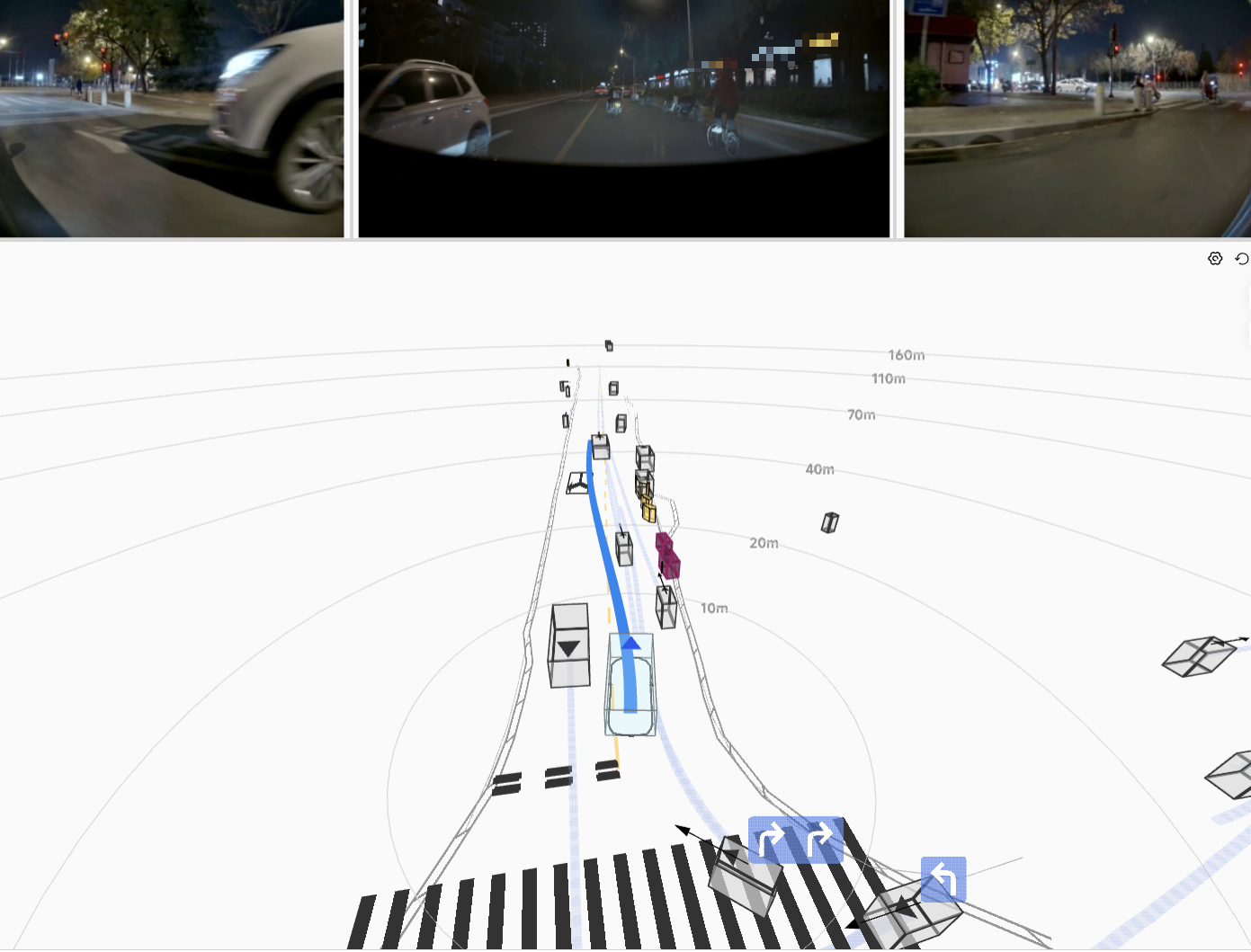
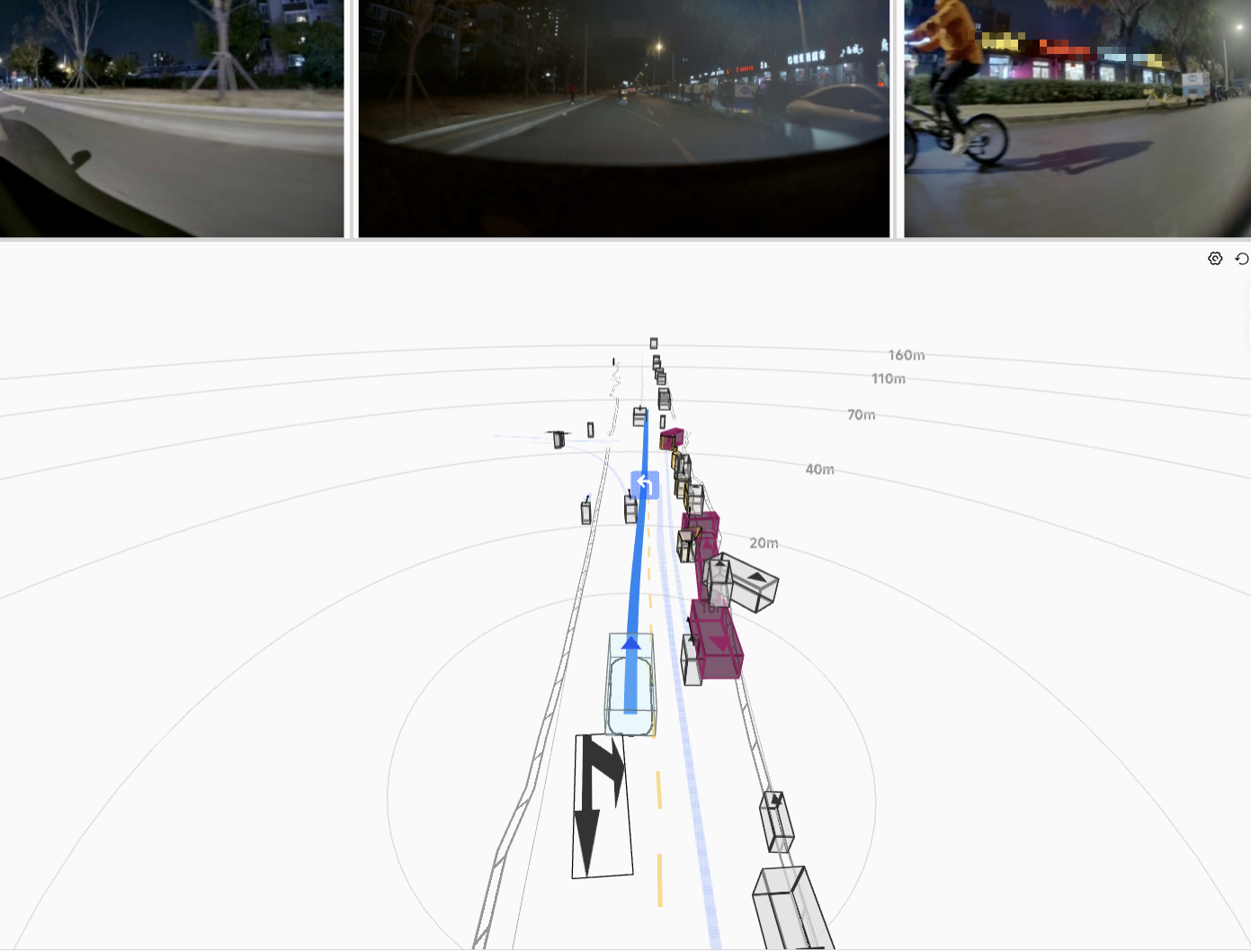
The resulting HDP-RL shows significant improvements in safety-critical scenarios
(yielding at intersections, VRU avoidance) while preserving overall driving stability—completing
the progression from "it drives" to "it drives safely."