🔥[2024-01-16]: Our paper Safe Offline Reinforcement Learning with Feasibility-Guided Diffusion Model has been accepted by ICLR 2024.
How can we train a diffusion policy to satisfy hard constraints using only supervised objectives, without employing iterative Lagrangian-based methods?
Safe offline reinforcement learning is a promising way to bypass risky online interactions towards safe policy learning. Most existing methods only enforce soft constraints, i.e., constraining safety violations in expectation below thresholds predetermined. This can lead to potentially unsafe outcomes, thus unacceptable in safety-critical scenarios. An alternative is to enforce the hard constraint of zero violation. However, this can be challenging in offline setting, as it needs to strike the right balance among three highly intricate and correlated aspects: safety constraint satisfaction, reward maximization, and behavior regularization imposed by offline datasets. Interestingly, we discover that via reachability analysis of safe-control theory, the hard safety constraint can be equivalently translated to identifying the largest feasible region given the offline dataset. This seamlessly converts the original trilogy problem to a feasibility-dependent objective, i.e., maximizing reward value within the feasible region while minimizing safety risks in the infeasible region. Inspired by these, we propose FISOR (FeasIbility-guided Safe Offline RL), which allows safety constraint adherence, reward maximization, and offline policy learning to be realized via three decoupled processes, while offering strong safety performance and stability. In FISOR, the optimal policy for the translated optimization problem can be derived in a special form of weighted behavior cloning, which can be effectively extracted with a guided diffusion model thanks to its expressiveness. Moreover, we propose a novel energy-guided sampling method that does not require training a complicated time-dependent classifier to simplify the training. We compare FISOR against baselines on DSRL benchmark for safe offline RL. Evaluation results show that FISOR is the only method that can guarantee safety satisfaction in all tasks, while achieving top returns in most tasks.
We can predetermine the approximately largest feasible region using offline datasets, without the need to train a policy. Compared to the commonly used cost state-value function, our approach yields a lower approximation error.
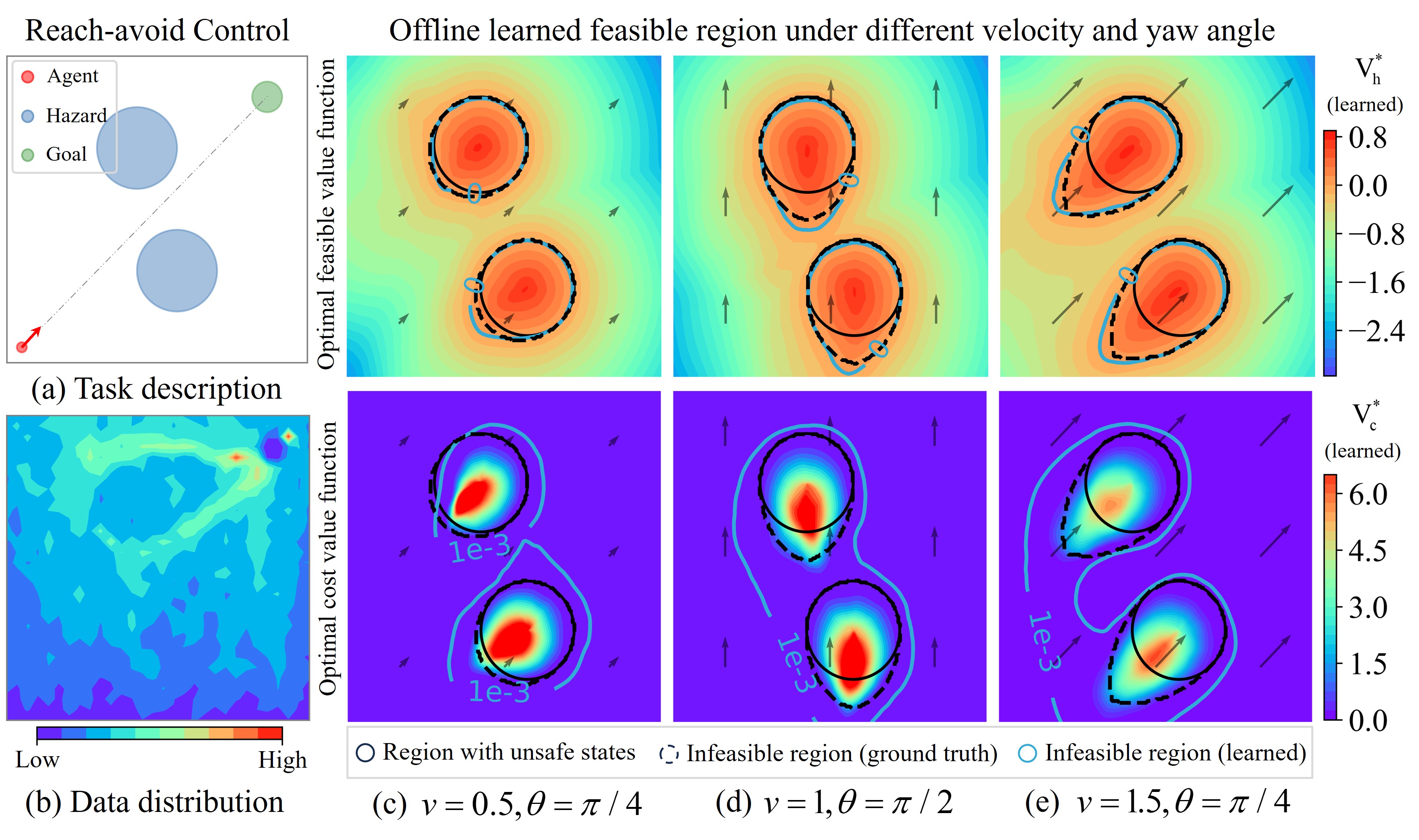
Figure 1: (a) Reach-avoid control task: the agent (red) aim to reach the goal (green) while avoiding hazards (blue). (b) Offline data distribution. (c)-(e) Comparisons with the feasible region learned by feasible value {s|V*_h(s)<=0} and cost value {s|V*_c(s)<=1e-3}.
We propose a feasibility-dependent objective, i.e., maximizing reward value within the feasible region while minimizing safety risks in the infeasible region. In FISOR, the optimal policy for the optimization problem can be derived in a special form of weighted behavior cloning. Moreover, we propose a novel energy-guided sampling method that does not require training a complicated time-dependent classifier to simplify the training. No more Lagrangian.
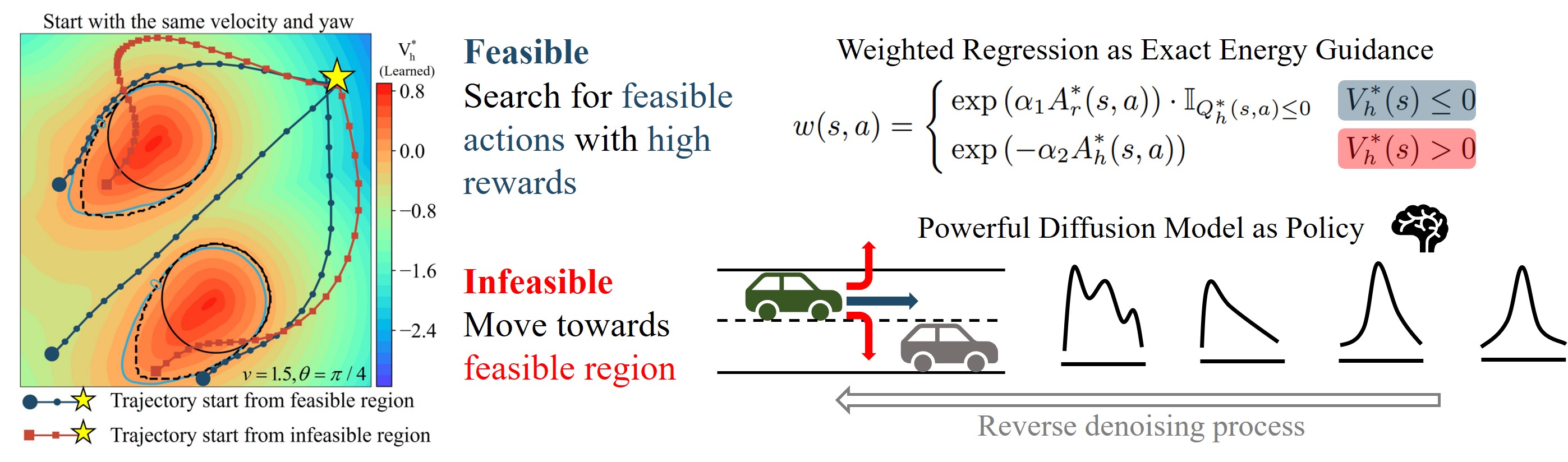
Figure 2: Feasibility-guided diffusion model with time-independent classifier-guided sampling method.
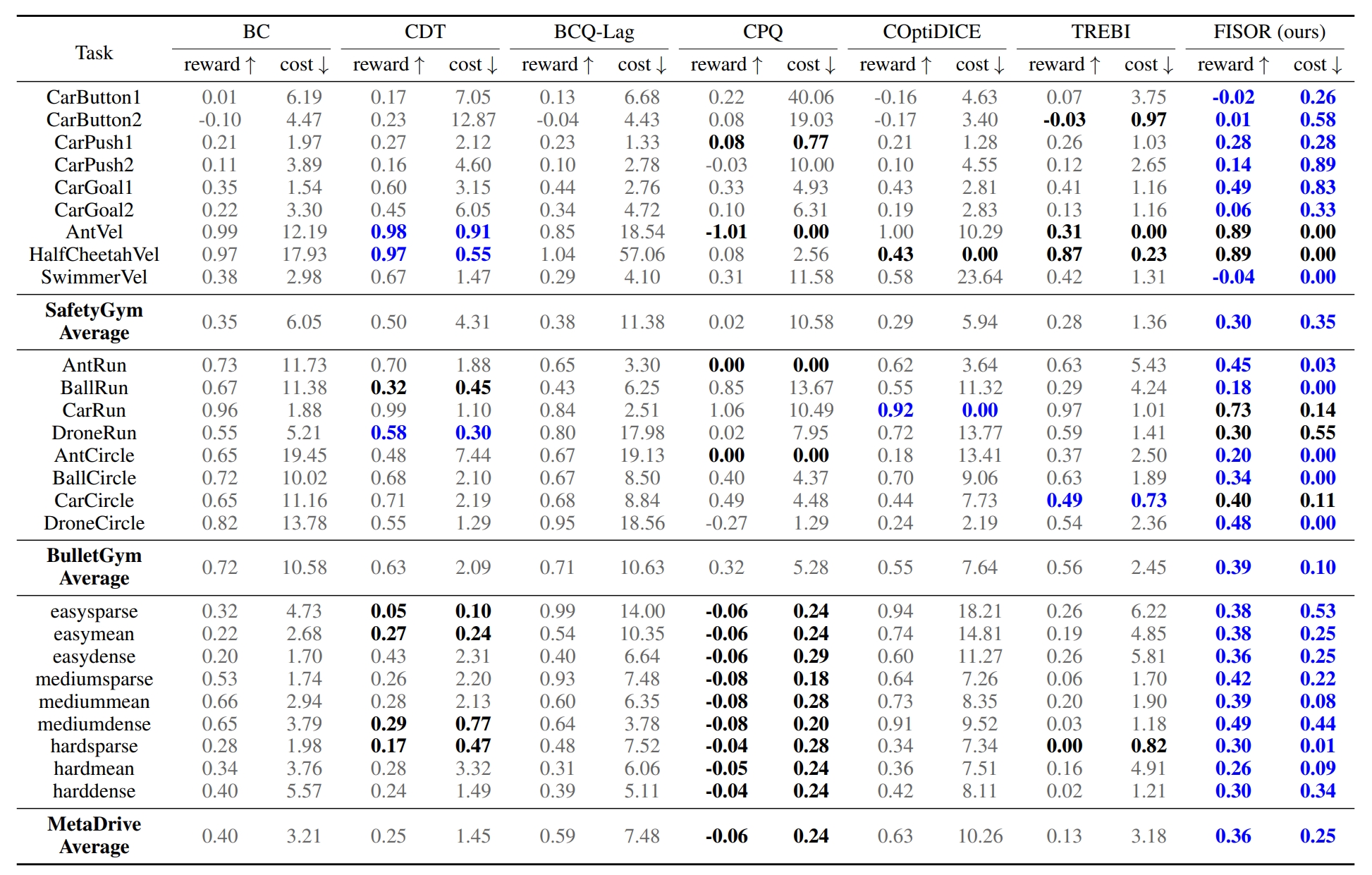
Table 1: Normalized DSRL benchmark results. Each value is averaged over 20 evaluation episodes and 3 seeds. Blue: Safe agents with the highest reward. Gray: Unsafe agents. Bold: safe agents whose normalized cost is smaller than 1.
We evaluate the sensitivity of cost limit selection for soft-constraint-based methods to demonstrate the effectiveness of hard constraint. Results shows that most soft-constraint-based methods are highly sensitive to the value of cost limit. In some cases, choosing a small cost limit even leads to an increase in the final cost. ] This shows that it is difficult for these methods to select the right cost limit to achieve the best performance, which requires task-specific tuning. In contrast, our algorithm, which considers hard constraints, does not encounter this issue and achieves superior results using only one group of hyperparameters.
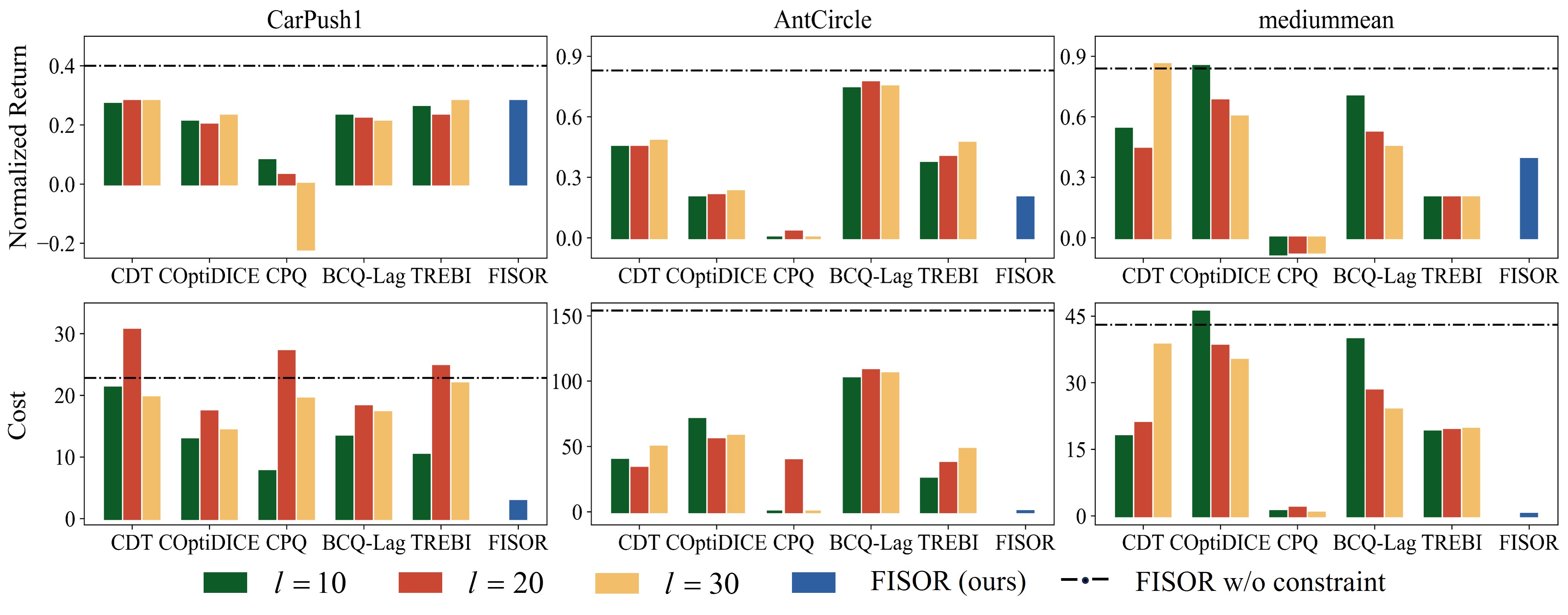
Figure 3: Soft constraint sensitivity experiments for cost limit.
We select some competitive baselines that achieve relatively good safety and reward performances in Table 1 and train them with 1/2 and 1/10 of the data volume. FISOR still meets safety requirements and demonstrates more stable performance compared to other methods, although a reduction in data volume weakens FISOR's safety a little. We believe FISOR enjoys such good stability as it decouples the intricate training processes of safe offline RL, which greatly enhances training performances.
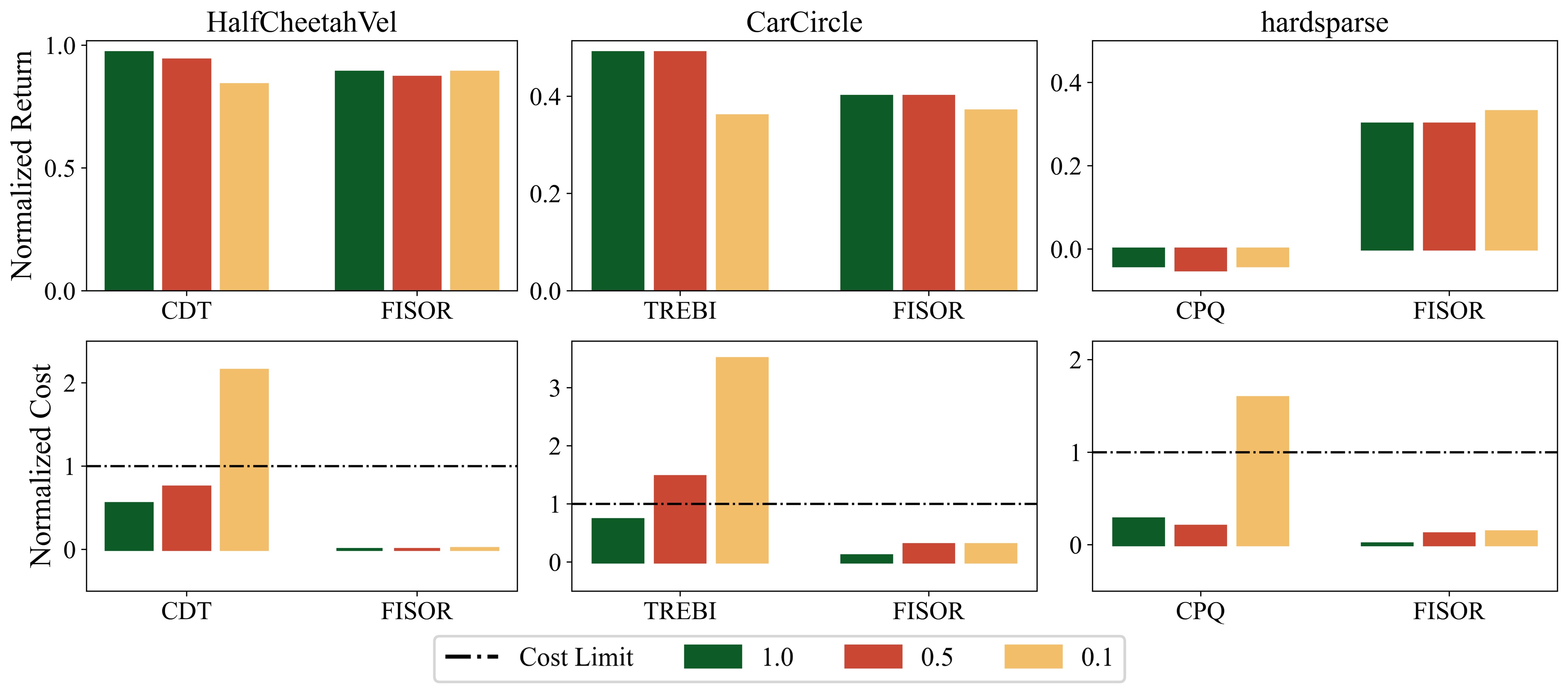
Figure 4: Data quantity sensitivity experiment results.
@article{zheng2024safe,
title={Safe Offline Reinforcement Learning with Feasibility-Guided Diffusion Model},
author={Zheng, Yinan and Li, Jianxiong and Yu, Dongjie and Yang, Yujie and Li, Shengbo Eben and Zhan, Xianyuan and Liu, Jingjing},
journal={arXiv preprint arXiv:2401.10700},
year={2024}
}